The Crossref Nominating Committee is inviting expressions of interest to join the Board of Directors of Crossref for the term starting in January 2025. The committee will gather responses from those interested and create the slate of candidates that our membership will vote on in an election in September.
Expressions of interest will be due Monday, May 27th, 2024
This is an exciting time to join the board, as we have a number of active projects underway: We are considering resourcing Crossref for a sustainable future and board members will be part of deciding any changes to our fees scheme and overseeing its implementation.
This past year has been a captivating journey of immersion within the Crossref community, a mix of online interactions and meaningful in-person experiences. From the engaging Sustainability Research and Innovation Conference in Port Elizabeth, South Africa, to the impactful webinars conducted globally, this has been more than just a professional endeavour; it has been a personal exploration of collaboration, insights, and a shared commitment to pushing the boundaries of scholarly communication.
One of the challenges that we face in Labs and Research at Crossref is that, as we prototype various tools, we need the community to be able to test them. Often, this involves asking for deposit to a different endpoint or changing the way that a platform works to incorporate a prototype.
The problem is that our community is hugely varied in its technical capacity and level of ability when it comes to modifying their platform.
When each line of code is written it is surrounded by a sea of context: who in the community this is for, what problem we’re trying to solve, what technical assumptions we’re making, what we already tried but didn’t work, how much coffee we’ve had today. All of these have an effect on the software we write.
By the time the next person looks at that code, some of that context will have evaporated.
Not sure if you’re using iThenticate v1 or iThenticate v2? More here.
Not sure whether you’re an account administrator? Find out here.
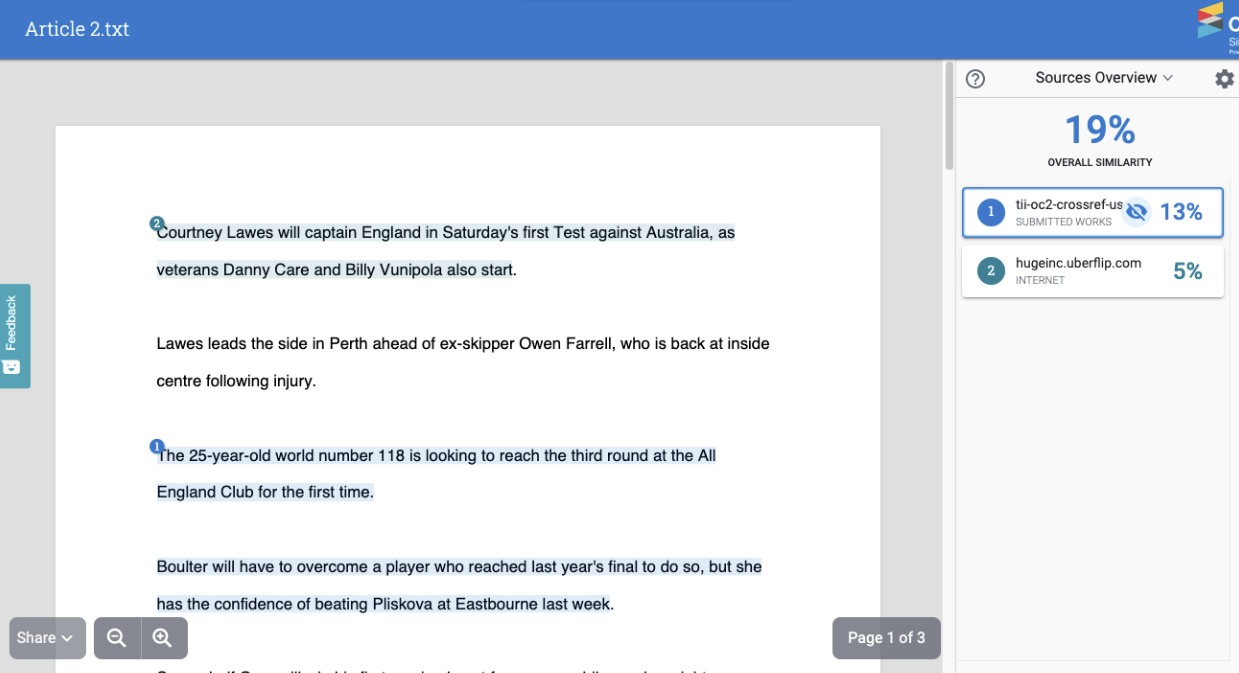
The Submitted Works repository (or Private Repository) is a new feature in iThenticate v2 which is now available to Crossref members. This feature allows users to find similarity not just across Turnitin’s extensive Content Database but also across all previous manuscripts submitted to your iThenticate account for all the journals you work on. This would allow you to find collusion between authors or potential cases of duplicate submissions.
How does this work?
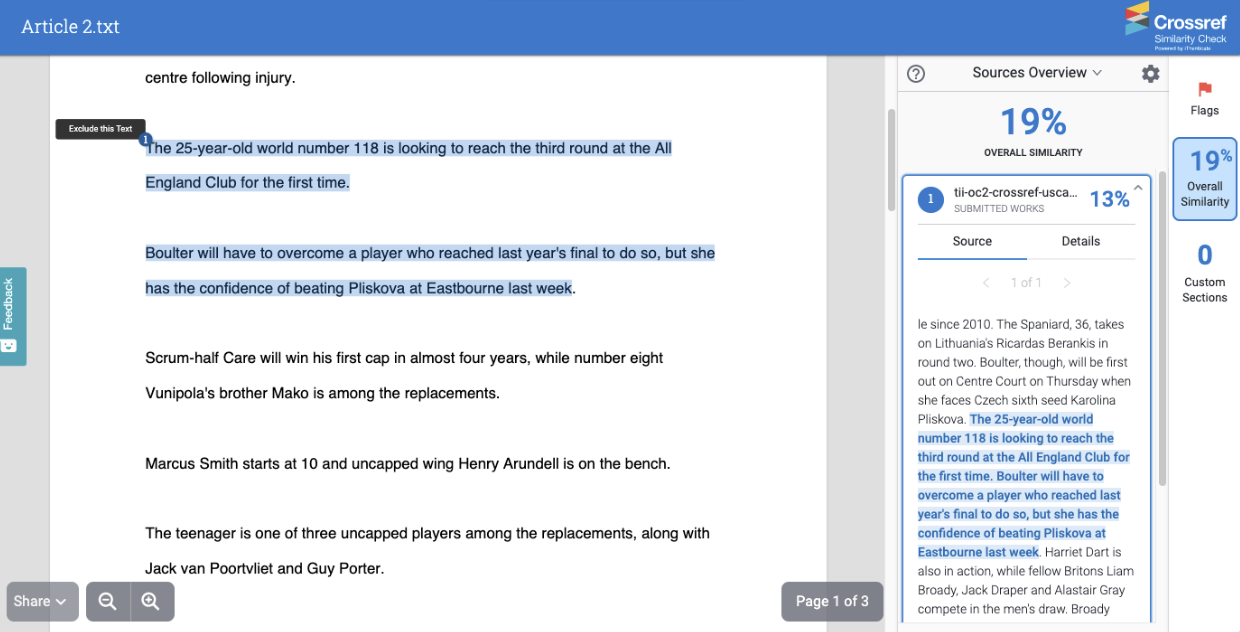
You have received a manuscript from Author 1 and have decided to index this manuscript into your Submitted Works repository. At some point later you receive a new manuscript from Author 2. When generating your Similarity Report, you have decided to check against your Submitted Works repository. There is a paragraph in the manuscript from Author 2 which matches a paragraph in the manuscript from Author 1. This would be highlighted within your Similarity Report as a match against your Submitted Works repository.
By clicking on this match you can see the full text of the submission you’ve matched against:
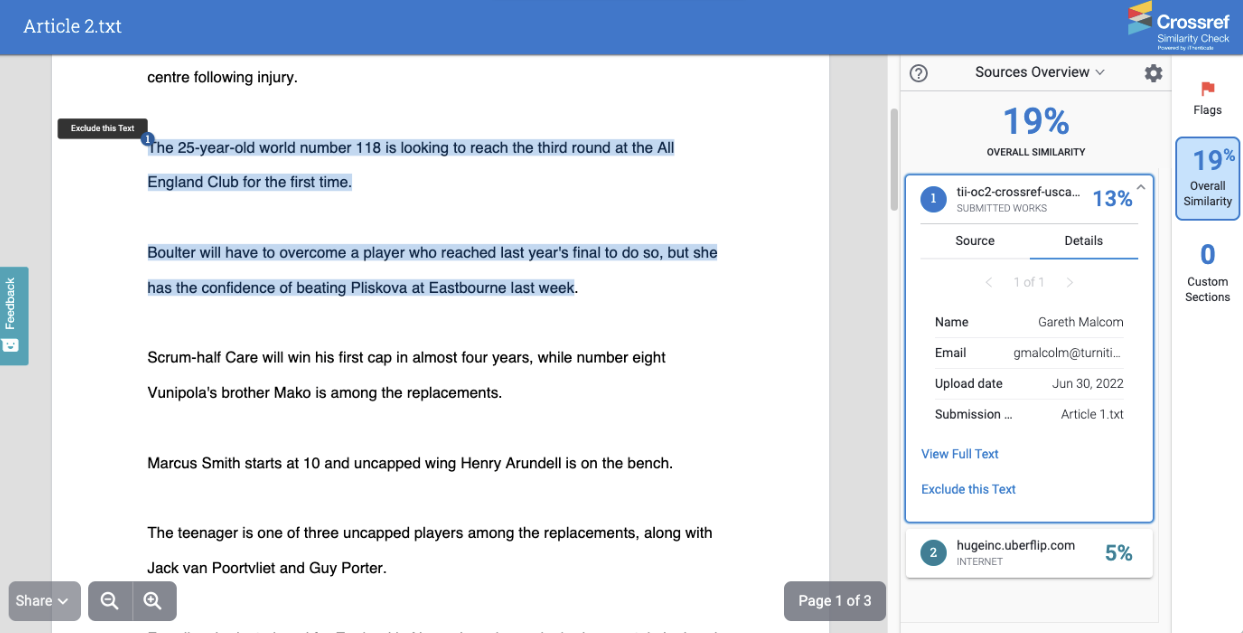
And details about the submission, such as the name and email address of the user who submitted it, the date it was submitted and the title of the submission:
The ability to see the full source text and the details can both be switched off individually.
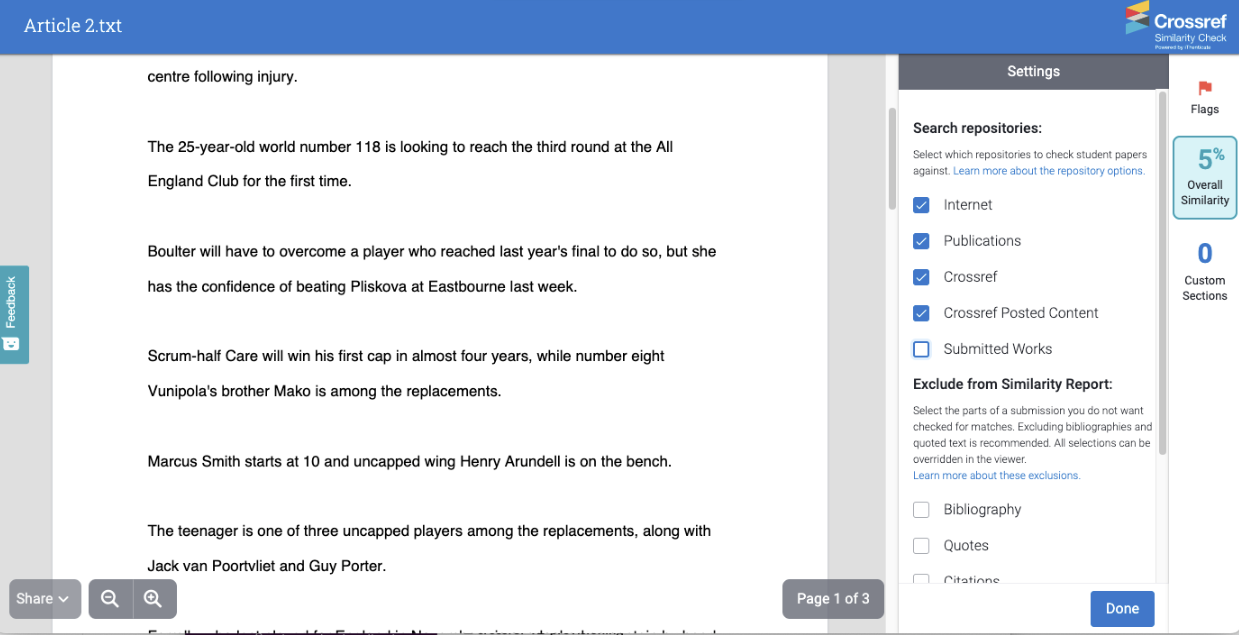
As with all matches, they can be excluded from the Sources Overview panel or you can turn off matches against all Submitted Works from the settings: