The Crossref Nominating Committee is inviting expressions of interest to join the Board of Directors of Crossref for the term starting in January 2025. The committee will gather responses from those interested and create the slate of candidates that our membership will vote on in an election in September.
Expressions of interest will be due Monday, May 27th, 2024
This is an exciting time to join the board, as we have a number of active projects underway: We are considering resourcing Crossref for a sustainable future and board members will be part of deciding any changes to our fees scheme and overseeing its implementation.
This past year has been a captivating journey of immersion within the Crossref community, a mix of online interactions and meaningful in-person experiences. From the engaging Sustainability Research and Innovation Conference in Port Elizabeth, South Africa, to the impactful webinars conducted globally, this has been more than just a professional endeavour; it has been a personal exploration of collaboration, insights, and a shared commitment to pushing the boundaries of scholarly communication.
One of the challenges that we face in Labs and Research at Crossref is that, as we prototype various tools, we need the community to be able to test them. Often, this involves asking for deposit to a different endpoint or changing the way that a platform works to incorporate a prototype.
The problem is that our community is hugely varied in its technical capacity and level of ability when it comes to modifying their platform.
When each line of code is written it is surrounded by a sea of context: who in the community this is for, what problem we’re trying to solve, what technical assumptions we’re making, what we already tried but didn’t work, how much coffee we’ve had today. All of these have an effect on the software we write.
By the time the next person looks at that code, some of that context will have evaporated.
Some of the typical users (outer) and uses (inner) of Crossref metadata
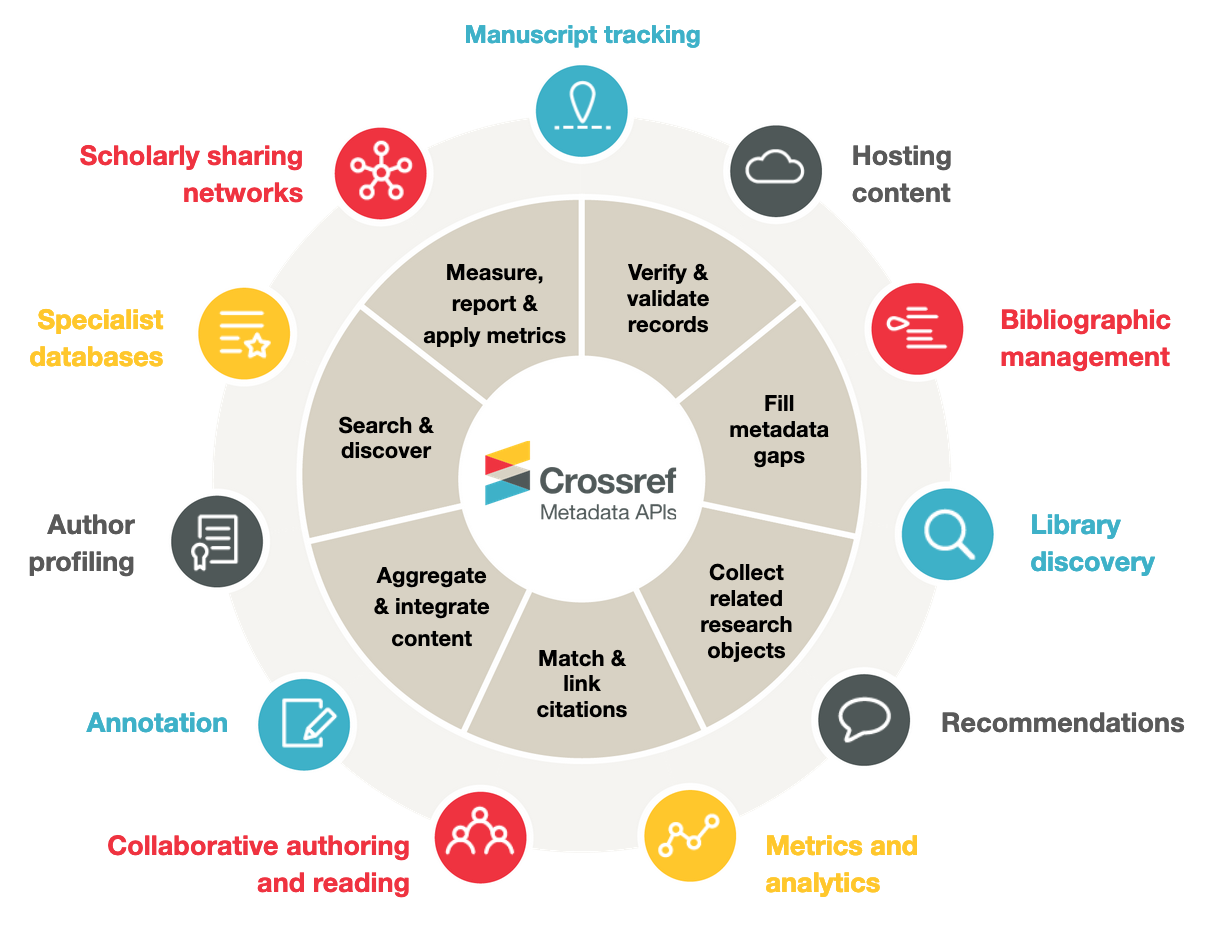
People using Crossref metadata need it for all sorts of reasons including metaresearch (researchers studying research itself such as through bibliometric analyses), publishing trends (such as finding works from an individual author or reviewer), or incorporation into specific databases (such as for discovery and search or in subject-specific repositories), and many more detailed use cases.
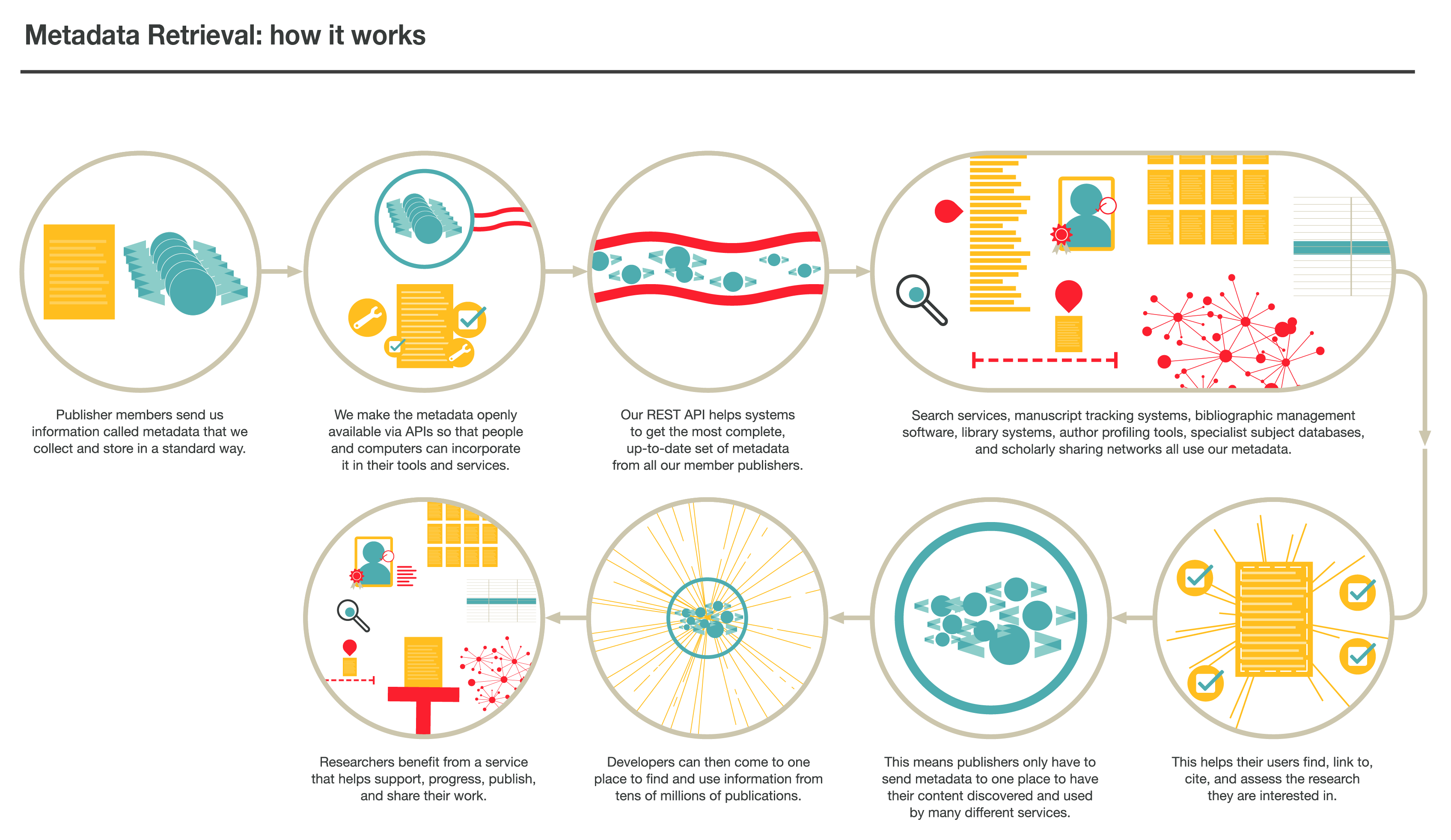
All Crossref metadata is open and available for reuse without restriction. Our
157874268 records include information about research objects like articles, grants and awards, preprints, conference papers, book chapters, datasets, and more. The information covers elements like titles, contributors, descriptions, dates, references, connecting identifiers such as Crossref DOIs, ROR IDs and ORCID iDs, together with all sorts of metadata that helps to determine provenance, trust, and reusability—such as funding, clinical trial, and license information.
Here is a comparison of the metadata retrieval options. Please note that all interfaces include Crossref test prefixes: 10.13003, 10.13039, 10.18810, 10.32013, 10.50505, 10.5555, 10.88888.
Feature / option
Metadata Search
Simple Text Query
REST API
XML API
OAI-PMH
OpenURL
Public data files
Metadata Plus (OAI-PMH + REST API)
Interface for people or machines?
People
People
People (low volume and occasional use) and machines
If you’d like to share a case study for how you use Crossref metadata, and be featured on our blog, please contact us.
Using content negotiation
The APIs listed here provide metadata in a variety of representations (also known as output formats). If you want to access our metadata in a particular representation (for example, RDF, BibTex, XML, CSL), you can use content negotiation to retrieve the metadata for a DOI in the representation you want. Content negotiation is supported by a number of DOI registration agencies including Crossref, DataCite, and mEDRA.
Obligations and fees for metadata retrieval
It is important that members understand that metadata is used by other software and services in the Crossref community. We encourage members to submit as much metadata as possible so that our APIs can include and deliver rich contextual information about their content.
If you’re using the public REST API, it is optional but encouraged to include your email address in header requests as this puts your query into the “polite” pool which has priority processing. Learn more about our REST API etiquette.
Crossref generally provides metadata without restriction; however, some abstracts contained in the metadata may be subject to copyright by publishers or authors.
How to participate - interfaces for people
Crossref provides a number of user interfaces to access Crossref metadata. Some are general-purpose, and others are more specialized.
Metadata Search is our primary user interface for searching and filtering of our metadata. It can be used to look up the DOI for a reference or a partial reference or a set of references, to look up metadata for a content item, submit a query on an author’s name, or find retractions registered with us. It can also be used to search and filter a number of elements, including funding data, ISSN, ORCID iDs, and more.
Simple Text Query is a tool designed to allow anyone to look up DOIs for multiple references. As such it’s particularly useful for members who want to link their references. Members can even use this tool to add linked references to their metadata.
How to participate - APIs for machines
We have a number of APIs for accessing metadata. There is one general-purpose API and several specialized ones. The specialized APIs are designed for our members so that they can manage their metadata or they are APIs based on standards that are popular in the community.
This API lets you look up a Crossref DOI for a reference, using a standard that is popular in the library community, and particularly with link resolver services.
This API outputs in XML and uses a standard popular in the library community to harvest metadata. The OAI-PMH API is optimized to return a list of results matching the query parameters (such as publication year). The OAI-PMH API is included in the Metadata Plus service.
While the public data files are not an API, they are freely available bulk downloads of the full Crossref metadata corpus, published annually. It can be downloaded via Academic Torrents, or directly from AWS for a small fee.
We support a range of tools and APIs to help you get metadata (and identifiers) out of our system. Some query interfaces will return only one match, and only if fairly strict requirements are met. These interfaces may be used to populate citations with persistent identifiers. Other interfaces will return a range of results and may be used to retrieve a variety of metadata records or match metadata when metadata, DOIs, or other identifiers (such as ORCID iD, ISSN, ISBN, funder identifier) are provided.
User interfaces
Metadata Search - any results containing the entered search terms will be returned. Search by full citation, title (or fragments of a title), authors, ISSN, ORCID, DOI (to retrieve metadata) and more.
Simple Text Query - cut-and-paste your reference list into the form and retrieve exact DOI matches.
APIs
REST API - a RESTful API that supports a wide range of facets and filters. By default, results are returned in JSON, and returning results in XML is an option. This API is currently publicly available (no account or token required), but there is a paid Metadata Plus service available on a token for those who require guaranteed service levels
XML API - the XML API will return a DOI that best fits the metadata supplied in the query. This API is suitable for automated population of citations with DOIs as the results are accurate and do not need evaluation. This API is available to members, or by supplying an email address.
OpenURL - used mostly by libraries but also available to members, or by providing an email address. Learn more about OpenURL access.
OAI-PMH - as well as a free public list option, we provide a subscription-only OAI-PMH interface that may be used to retrieve sets of metadata records (subscribers only)
GetResolvedRefs - retrieve DOIs matched with deposited references (members only)
Deposit harvester - retrieve DOIs and metadata for a given member (members only).
Page owner: Patrick Polischuk | Last updated 2020-April-08