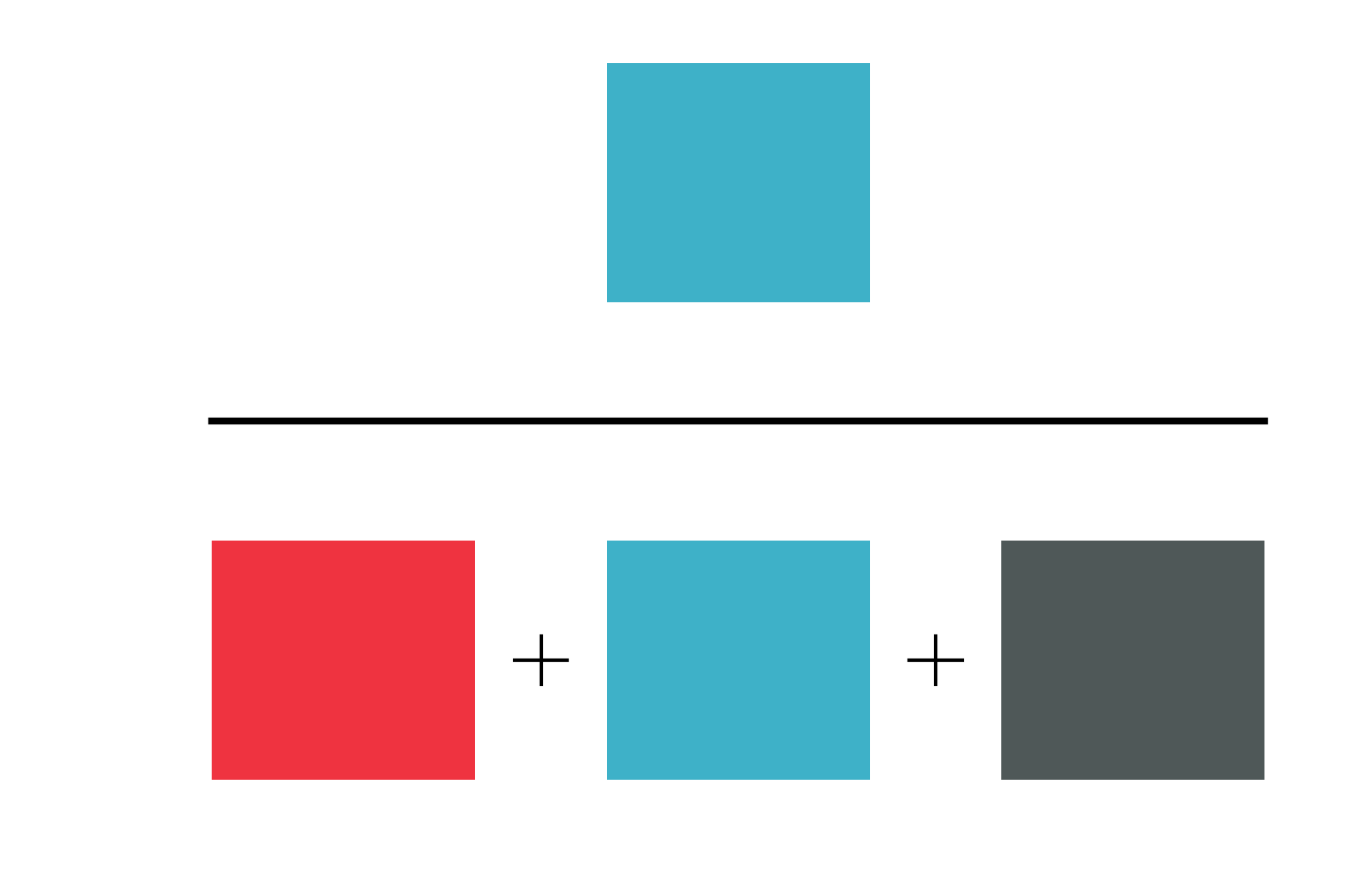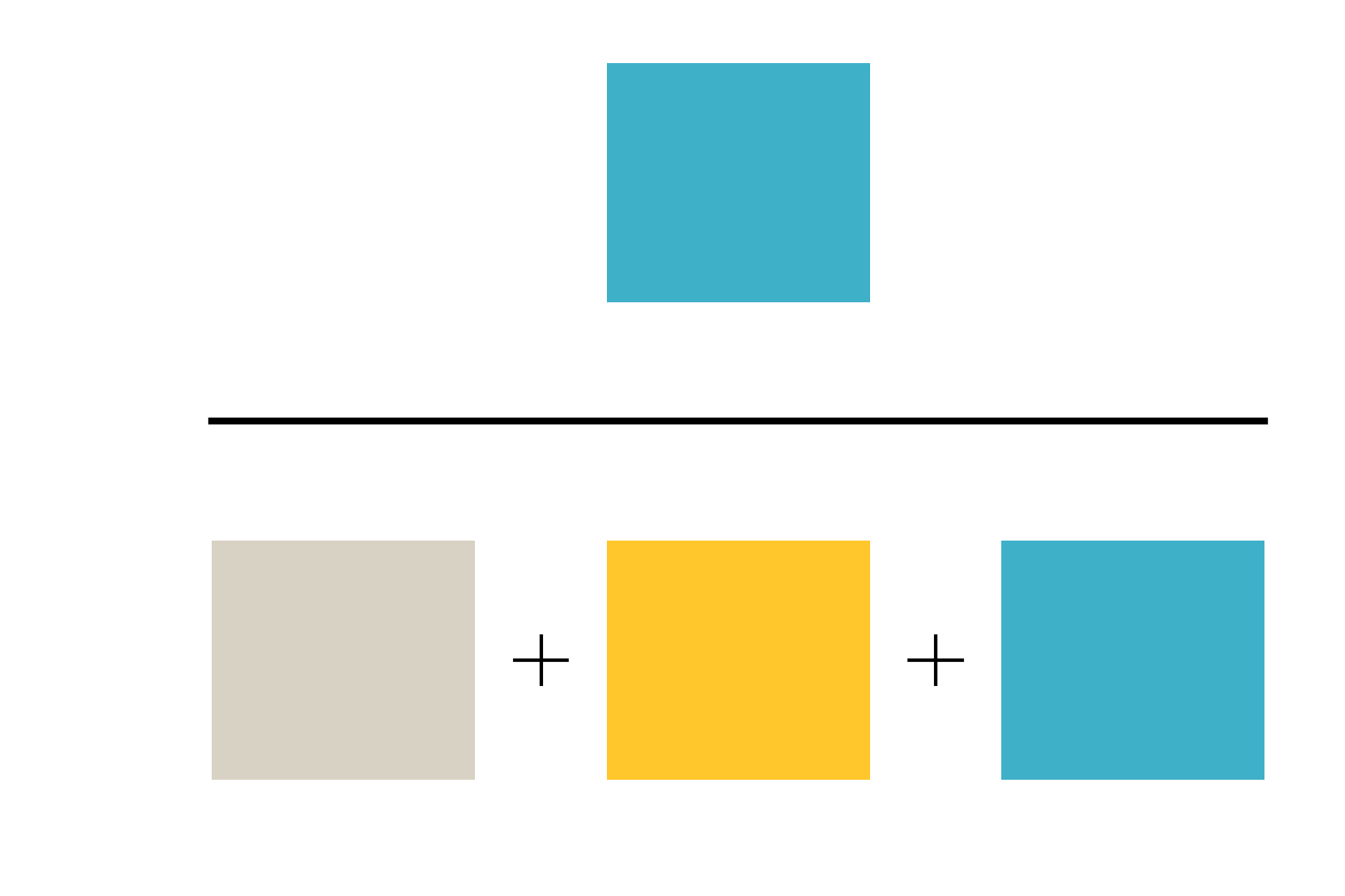The Crossref Nominating Committee is inviting expressions of interest to join the Board of Directors of Crossref for the term starting in January 2025. The committee will gather responses from those interested and create the slate of candidates that our membership will vote on in an election in September.
Expressions of interest will be due Monday, May 27th, 2024
This is an exciting time to join the board, as we have a number of active projects underway: We are considering resourcing Crossref for a sustainable future and board members will be part of deciding any changes to our fees scheme and overseeing its implementation.
This past year has been a captivating journey of immersion within the Crossref community, a mix of online interactions and meaningful in-person experiences. From the engaging Sustainability Research and Innovation Conference in Port Elizabeth, South Africa, to the impactful webinars conducted globally, this has been more than just a professional endeavour; it has been a personal exploration of collaboration, insights, and a shared commitment to pushing the boundaries of scholarly communication.
One of the challenges that we face in Labs and Research at Crossref is that, as we prototype various tools, we need the community to be able to test them. Often, this involves asking for deposit to a different endpoint or changing the way that a platform works to incorporate a prototype.
The problem is that our community is hugely varied in its technical capacity and level of ability when it comes to modifying their platform.
When each line of code is written it is surrounded by a sea of context: who in the community this is for, what problem we’re trying to solve, what technical assumptions we’re making, what we already tried but didn’t work, how much coffee we’ve had today. All of these have an effect on the software we write.
By the time the next person looks at that code, some of that context will have evaporated.
In my previous blog post, Matchmaker, matchmaker, make me a match, I compared four approaches for reference matching. The comparison was done using a dataset composed of automatically-generated reference strings. Now it’s time for the matching algorithms to face the real enemy: the unstructured reference strings deposited with Crossref by some members. Are the matching algorithms ready for this challenge? Which algorithm will prove worthy of becoming the guardian of the mighty citation network? Buckle up and enjoy our second matching battle!
TL;DR
I evaluated and compared four reference matching approaches: the legacy approach based on reference parsing, and three variants of search-based matching.
The dataset comprises 2,000 unstructured reference strings from the Crossref metadata.
The metrics are precision and recall calculated over the citation links. I also use F1 as a standard single-number metric that combines precision and recall, weighing them equally.
The best variant of search-based matching outperforms the legacy approach in F1 (96.3% vs. 92.5%), with the precision worse by only 0.9% (98.09% vs. 98.95%), and the recall better by 8.9% (94.56% vs. 86.85%).
Common causes of SBMV’s errors are: incomplete/erroneous metadata of the target documents, and noise in the reference strings.
The results reported here generalize to the subset of references in Crossref that are deposited without the target DOI and are present in the form of unstructured strings.
Introduction
In reference matching, we try to find the DOI of the document referenced by a given input reference. The input reference can have a structured form (a collection of metadata fields) and/or an unstructured form (a string formatted in a certain citation style).
In my previous blog post, I used reference strings generated automatically to compare four matching algorithms: Crossref’s legacy approach based on reference parsing and three variations of search-based matching. The best algorithm turned out to be Search-Based Matching with Validation (SBMV). SBMV uses our REST API’s bibliographic search function to select the candidate target documents, and a separate validation-scoring procedure to choose the final target document. The legacy approach and SBMV achieved very similar average precision, and SBMV was much better in average recall.
This comparison had important limitations, which affect the interpretation of these results.
First of all, the reference strings in the dataset might be too perfect. Since they were generated automatically from the Crossref metadata records, any piece of information present in the string, such as the title or the name of the author, will exactly match the information in Crossref’s metadata. In such a case, a matcher comparing the string against the record can simply apply exact matching and everything should be fine.
In real life, however, we should expect all sorts of errors and noise in the reference strings. For example, a string might have been manually typed by a human, so it can have typos. The string might have been scraped from the PDF file, in which case it could have unusual unicode characters, ligatures or missing and extra spaces. A string can also have typical OCR errors, if it was extracted from a scan.
These problems are typical for messy real-life data, and our matching algorithms should be robust enough to handle them. However, when we evaluate and compare approaches using the perfect reference strings, the results won’t tell us how well the algorithms handle harder, noisy cases. After all, even if you repeatedly win chess games against your father, it doesn’t mean you will likely defeat Garry Kasparov (unless, of course, you are Garry Kasparov’s child, in which case, please pass on our regards to your dad!).
Even though I attempted to make the data more similar to the noisy real-life data by simulating some of the possible errors (typos, missing/extra spaces) in two styles, this might not be enough. We simply don’t know the typical distribution of the errors, or even what all the possible errors are, so our data was probably still far from the real, noisy reference strings.
The differences in the distributions are a second major issue with the previous experiment. To build the dataset, I used a random sample from Crossref metadata, so the distribution of the cited item types (journal paper, conference proceeding, book chapter, etc.) reflects the overall distribution in our collection. However, the distribution in real life might be different if, for example, journal papers are on average cited more often than conference proceedings.
Similarly, the distribution of the citation styles is most likely different. To generate the reference strings, I used 11 styles distributed uniformly, while the real distribution most likely contains more styles and is skewed.
All these issues can be summarized as: the data used in my previous experiment is different from the data our matching algorithms have to deal with in the production system. Why is this important? Because in such a case, the evaluation results do not reflect the real performance in our system, just like the child’s score on the math exam says nothing about their score on the history test. We can hope my previous results accurately showed the strengths and weaknesses of each algorithm, but the estimations could be far off.
So, can we do better? Sure!
This time, instead of automatically-generated reference strings, I will use real reference strings found in the Crossref metadata. This will give us a much better picture of the matching algorithms and their real-life performance.
Evaluation
This time the evaluation dataset is composed of 2,000 unstructured reference strings from the Crossref metadata, along with the target true DOIs. The dataset was prepared mostly manually:
First, I drew a random sample of 100,000 metadata records from the system.
Second, I iterated over all sampled items, and extracted those unstructured reference strings, that do not have the DOI provided by the member.
Next, I randomly sampled 2,000 reference strings.
Finally, I assigned a target DOI (or null) to each reference string. This was done by verifying DOIs returned by the algorithms and/or manual searching.
The metrics this time are based on the citation links. A citation link points from the reference (or the document containing the reference) to the referenced (target) document.
When we apply a matching algorithm to a set of reference strings in our collection, we get a set of citation links between our documents. I will call those citation links returned links.
On the other hand, in our collection we have real, true links between the documents. In the best-case scenario, the set of true links and the set of returned links are identical. But we don’t live in a perfect world and our matching algorithms make mistakes.
To measure how close the returned links are to the true links, I used precision, recall and F1. This time they are calculated over all citation links in the dataset. More specifically:
Precision is the fraction of the returned links that are correct. Precision answers the question: if I see a citation link A->B in the output of a matcher, how certain can I be that paper A actually cites paper B?
Recall is the percentage of true links that were returned by the algorithm. Recall answers the question: if paper A cites paper B and B is in the collection, how certain can I be that the matcher’s output contains the citation link A->B?
F1 is the harmonic mean of precision and recall.
In the previous experiment, I also used precision, recall and F1, but they were calculated for each target document and then averaged. This time precision, recall and F1 are not averaged but simply calculated over all citation links. This is a more natural approach, since now the dataset comprises isolated reference strings rather than target documents, and in practice each target document has at most one incoming reference.
I tested the same four approaches as before:
the legacy approach, based on reference parsing
SBM with a simple threshold, which searches for the reference string in the search engine and returns the first hit, if its relevance score exceeds the predefined threshold
SBM with a normalized threshold, which searches for the reference string in the search engine and returns the first hit, if its relevance score divided by the string length exceeds the predefined threshold
SBMV, which first applies SBM with a normalized threshold to select a number of candidate items, and a separate validation procedure is used to select the final target item
All the thresholds are parameters which have to be set prior to the matching. The thresholds used in the experiments were chosen using a separate dataset, as the values maximizing the F1 of each algorithm.
Results
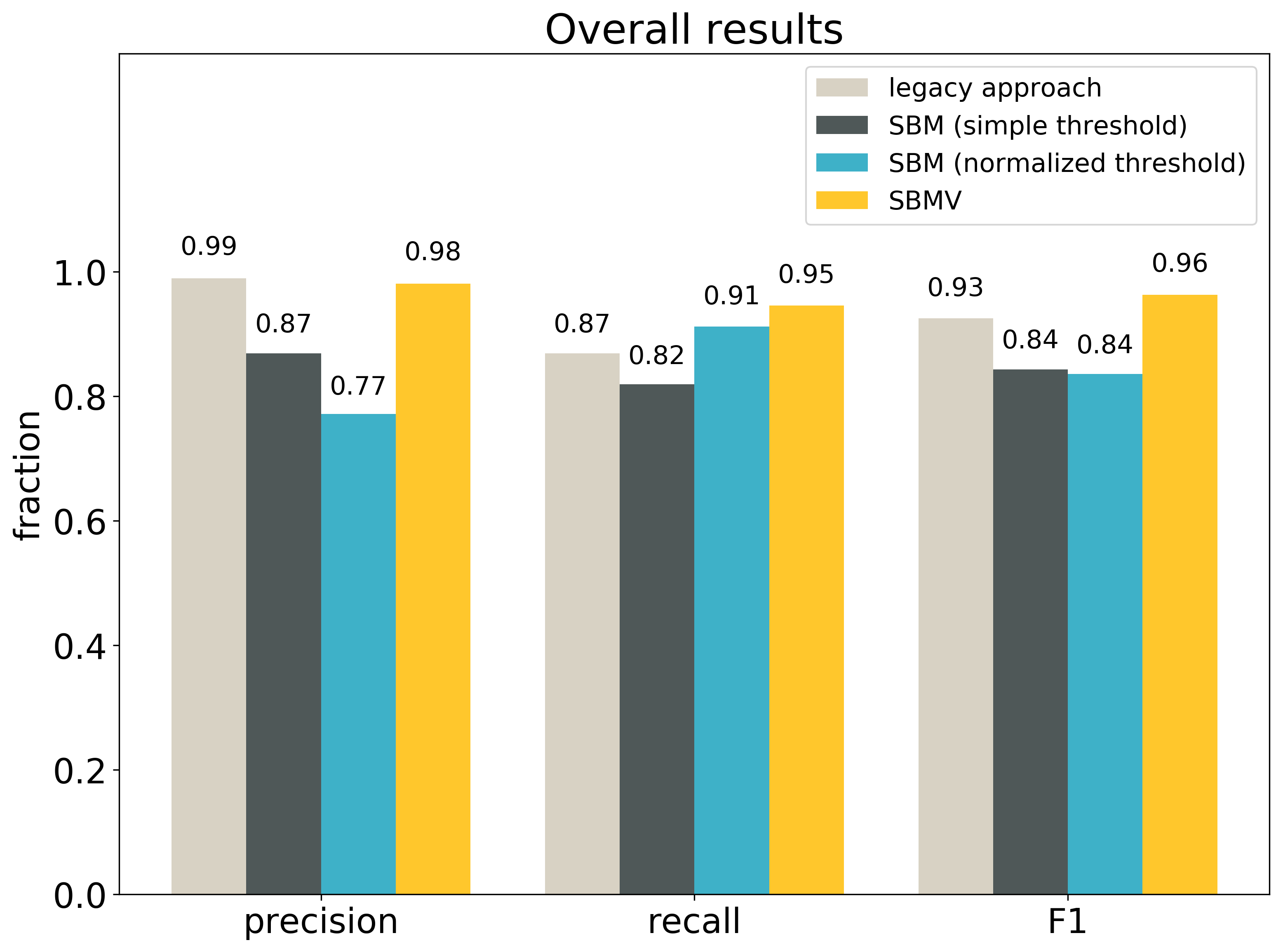
The plot shows the overall results of all tested approaches:
The exact values are also given in the table (the best result for each metric is bolded):
precision
recall
F1
legacy approach
0.9895
0.8685
0.9251
SBM (simple threshold)
0.8686
0.8191
0.8431
SBM (normalized threshold)
0.7712
0.9121
0.8358
SBMV
0.9809
0.9456
0.9629
As we can see, the legacy approach is the best in precision, slightly outperforming SBMV. In recall, SBMV is clearly the best, which also decided about its victory over the legacy approach in F1.
How do these results compare to the results from my previous blog post? The overall trends (the legacy approach slightly outperforms SBMV in precision, and SBMV outperforms the legacy approach in recall and F1) are the same. The most important differences are: 1) on the real dataset SBM without validation is worse than the legacy approach, and 2) this time the algorithms achieved much higher recall. These differences are most likely related to the difference in data distributions explained before.
SBMV’s strengths and weaknesses
Let’s look at a few example cases where SBMV successfully returned the correct DOI, while the legacy approach failed.
Lundqvist D, Flykt A, Ohman A: The Karolinska Directed Emotional Faces - KDEF, CD ROM from Department of Clinical Neuroscience, Psychology section, Karolinska Institutet. 1998
The target item is a dataset, which means unusual metadata fields and an unusual reference string.
Schminck, A. , ‘The Beginnings and Origins of the “Macedonian” Dynasty’ in J. Burke and R. Scott , eds., Byzantine Macedonia: Identity, Image and History (Melbourne, 2000), 61–8.
This is an example of a book chapter. The reference string contains special quotes and dash characters.
R. Schneider,On the Aleksandrov-Fenchel inequality, inDiscrete Geometry and Convexity (J. E. Goodman, E. Lutwak, J. Malkevitch and R. Pollack, eds.), Annals of the New York Academy of Sciences440 (1985), 132–141.
This is another example of a reference string with missing spaces.
F. Cappello, A. Geist, W. Gropp, S. Kale, B. Kramer, and M. Snir. Toward exascale resilience: 2014 update. Supercomputing frontiers and innovations, 1(1), 2014.
In this case authors are missing in the Crossref metadata.
Li KZ, Shen XT, Li HJ, Zhang SY, Feng T, Zhang LL. Ablation of the Carbon/carbon Composite Nozzle-throats in a Small Solid Rocket Motor[J]. Carbon, 2011, 49: 1 208–1 215
In this case the space is missing between the title and the journal name.
Ono , N. 2011 Stable and fast update rules for independent vector analysis based on auxiliary function technique Proceedings of IEEE Workshop on Applications of Signal Processing to Audio and Acoustics 189 192
In this case both title and journal name are missing from the reference string.
We can see from these examples that SBMV is fairly robust and able to deal with a small amount of noise in the metadata and reference strings.
What about the errors SBMV made? From the perspective of citation links, we have two types of errors:
False positives: incorrect links returned by the algorithm.
False negatives: links that should have been returned but weren’t.
When we apply SBMV instead of the legacy approach, the fraction of false positives within the returned links increases from 1.05% to 1.91%, and the fraction of false negatives within the true links decreases from 13.15% to 5.44%. This means with SBMV:
1.91% of the links in the algorithm’s output are incorrect
5.44% of the true links are not returned by the algorithm
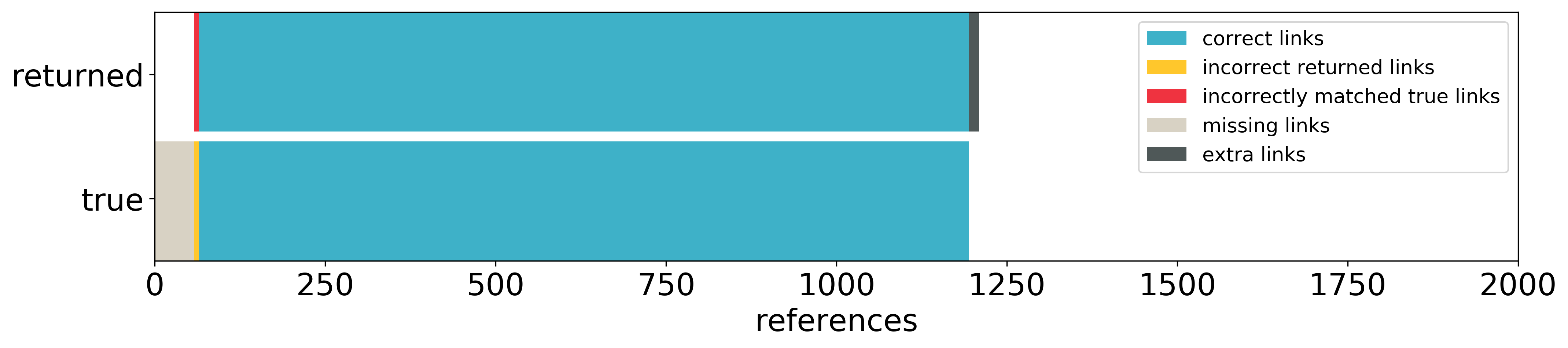
We can also classify all the references in the dataset into several categories, based on the values of true and returned DOIs:
We have the following categories:
References matched to correct DOIs (1129 cases, returned and true blue)
References correctly not matched to anything (791 cases, returned and true white)
References not matched to anything, when they should be (58 cases, returned white, true grey)
References matched to wrong DOIs (7 cases, returned red, true yellow)
References matched to something, when they shouldn’t be matched to anything (15 cases, returned black, true white)
Note that in terms of these categories, precision is equal to:
And recall is equal to:
What are the most common causes of SBMV’s errors?
Incomplete or incorrect Crossref metadata. Even a perfect reference string formatted in the most popular citation style will not be matched, if the target record in the Crossref collection has many missing or incorrect fields.
Similarly, missing or incorrect information in the reference string is very problematic for the matchers.
Errors/noise in the reference string, such as:
HTML/XML markup not stripped from the string
multiple references mixed in one string
spacing issues and typos
In a few cases a document related to the real target was matched, such as the book instead of its chapter, or the conference proceedings paper instead of the thesis.
Limitations
The most important limitation is the size of the dataset. Every item had to be verified manually, which significantly limited the possibility of creating a large set and also using a lot of independent sets.
Finally, the numbers reported here still don’t reflect the overall precision and recall of the current links in the Crossref metadata. This is because:
we still use the legacy approach for matching,
some references are deposited along with the target DOIs and are not matched by Crossref, these links are not analyzed here, and
in Crossref we have both unstructured and structured references, and in this experiment only the unstructured ones were tested.
What’s next?
The next experiment will be related to the structured references. Similarly as here, I will try to estimate the performance of the search-based matching approach and compare it to the performance of the legacy approach.
The evaluation framework, evaluation data and experiments related to the reference matching are available in the repository https://github.com/CrossRef/reference-matching-evaluation. Future experiments will be added there as well.